How to Build a Lipcolour Search Engine with Python
This is a sort-of transcript (written from memory a few weeks after the event, so some of the details may be different) of a talk I gave at the PyLadies Stockholm Meetup in Late October. The meetup was organised in co-operation with H&MxAI analytics department.
Slide 1

Hello everyone and thank you for giving me the opportunity to give a talk at PyLadies Stockholm. Today, I’m going to talk a bit about how and why I decided to build a search engine for lipcolours. Back in early 2018, I was thinking about two questions. First, someone online was wondering what was the colour of the lipstick that Scully played by Gillian Anderson in the series X-files wore on screen. Since the show was filmed quite a while ago, it was likely that these colours no longer existed, but perhaps it would be possible to find close enough shade matches? This occurred at about the same time as I started playing with facial landmark recognition algorithms and had written up some simple scripts to extract a lipcontour and a lipstick colour from the image of a person wearing makeup. So I quickly found a few photos of scully and started extracting the lipcolours she was wearing.
At about the same time as I was investigating this idea of an automated “what lipcolour is she wearing” app, I was also trying to find a matte lipstick in a dark yellow, almost ochre colour. After browsing the websites of countless brands and e-commerce stores, I’d become frustrated with the fact that seeing which colours were on offer by a given manufacturer, required clicking nd sifting through tens of irrelevant web pages.
These two ideas came together and I decided to try and construct a lipcolour search engine that would help users answer questions such as: which brands have a product in this exact shade of yellow or red or pink? Which liquid lip products are available in a metallic violet? What about specific shades of red in a satin finish? What are some colour shades similar to Charlotte Tilbury’s Matte Revolution lipstick in Pillow Talk? In this talk, I’ll go through how I solved this problem.
Slide 2

Here are the two people building this. I’m working on the backend and frontend of the application as well as the colour extraction and machine learning infrastructure behind the colour recognizer and my friend Fida is working on the visual imagery of the blog, the site and various social media streams.
Slide 3

The one piece of software that most of us use everyday, sometimes even without noticing, is a search engine. And most commonly this search engine is Google. We are used to formulating our query as a piece of text, entering it into the search bar and hitting search. The results will be something like this.
Slide 4
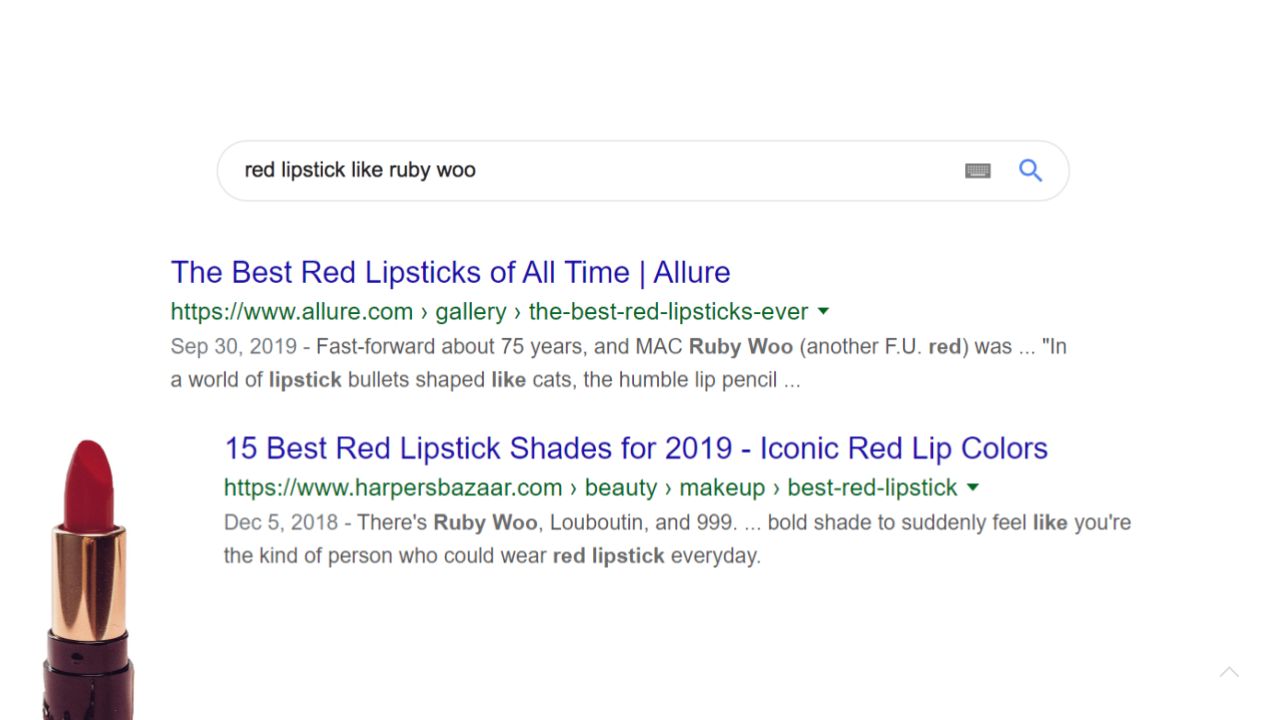
Google’s crawlers continuously scan and index the millions of websites that make up the world wide web. Then when you enter a query, an algorithm analyses the text in the search box and scans through its database of millions of websites to see which ones would contain strings that most closely match your query.
Here we have entered the query “red lipstick like Ruby Woo”. For those who are not familiar with the cosmetics world, Ruby Woo is the name of a cult lipstick manufactured by the company MAC Cosmetics. Among lipstick enthusiasts, Ruby Woo is considered somewhat of a “universal red”, a shade of red that will look good on most skintones. A common search query that people are interested in finding so called “dupes” of Ruby Woo - products that have the same colour shades but are cheaper or more widely available (if MAC for some reason is not retailing in a given country, for example) or perhaps available in a different product format (these days, lipcolours can come in a classic lipstick format, or a liquid lipstick, lip crayon or even a lip oil).
As we can see, Google has produced search results that incorporate elements of our query “red lisptick like Ruby Woo”, but this does not directly answer the question: which lipstick are close enough in colour shade to Ruby Woo?
Slide 5

Moreover, describing a colour in words can be difficult and ambiguous. People may describe the same colour using different words. For example, how would you describe these shades of blue and pink?
Slide 6
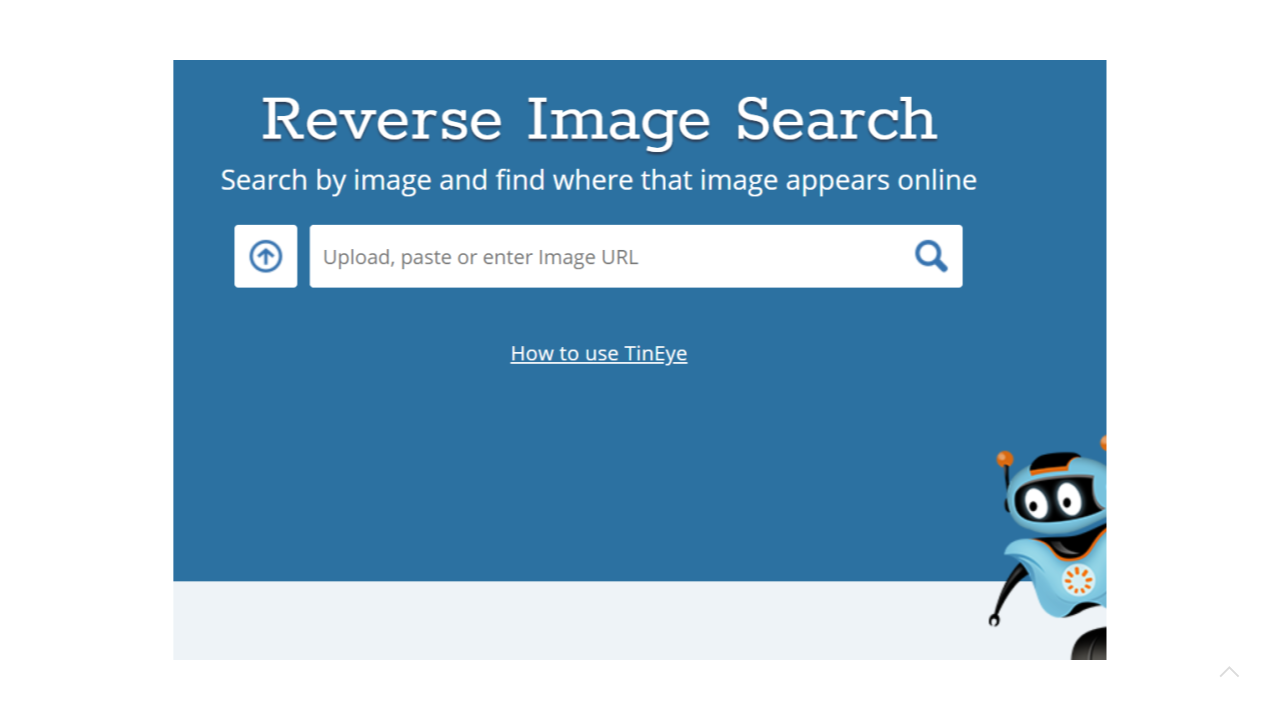
Technologists have been thinking about non-textual search for a while and one product that has been quite popular in the space of visual search is a reverse image search engine. This is a screenshot from a product developed by the company TinEye and it is used for example to track copyright violations. Instead of text, the search engine takes as input an image and produces search results that are, in some sense, similar to the image entered as a query.
Slide 7
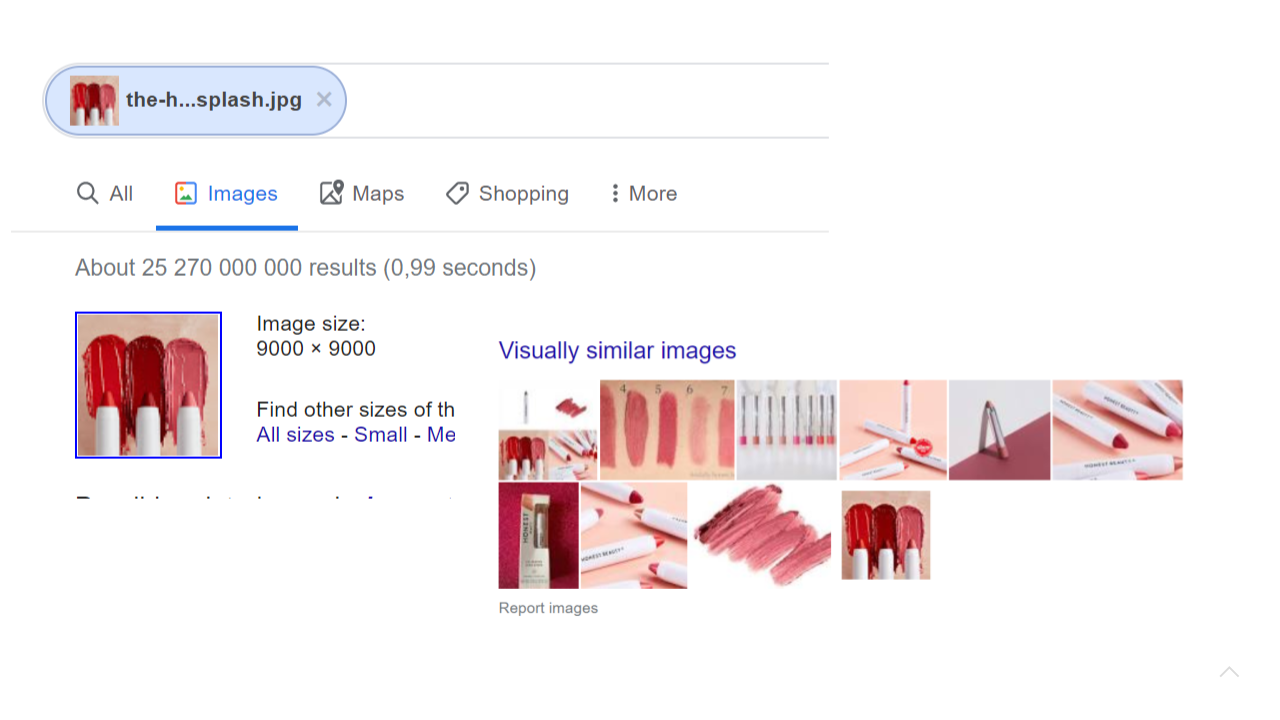
Google has produced its own version of a reverse image search engine. You upload an image and Google will search through its database of crawled images for ones that are closest to the image (for some definition of closest). Here is an example search. As we can see it does quite a good job at producing images with a similar colour scheme, but it still does not get us any closer to answering the actual questions of: “display the products that are closest in colour to the ones I am searching for”.
Slide 8

The problem becomes even more difficult if we want to know “what lipcolour is she wearing in this image?”.We can try out Google’s reverse image search to see how close this will get us to the answer.
Slide 9

The result images are visually similar to the image we searched for, but we can see that the reverse image search engine is focused on matching the general colour scheme and subject matter of the photo (all of the results are photos of women wearing clothing in blueish shades). We haven’t really gotten any results that would help us figure out which lipcolour could be the one the model is wearing.
Slide 10
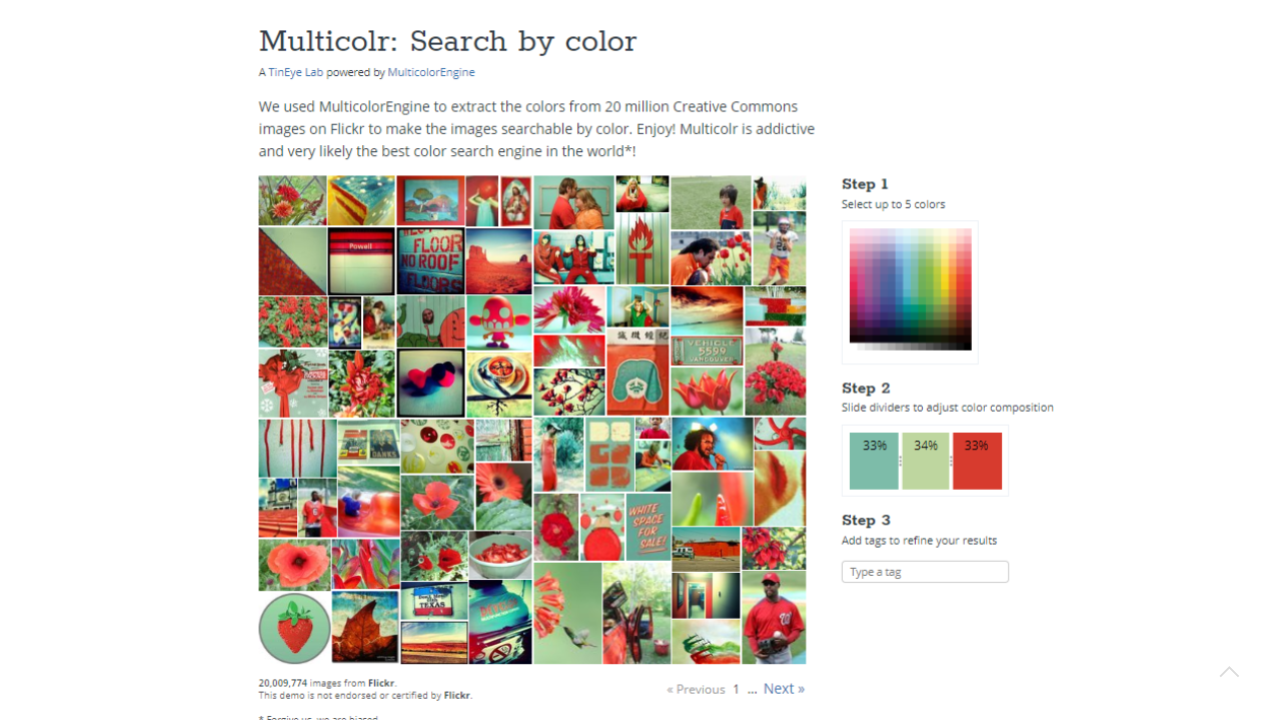
So we need some sort of colour search engine that can help us with various queries. Here is an example of a colour search engine developed by the company TinEye, but once again, it is not as niche or specialised as we could hope for.
Slide 11
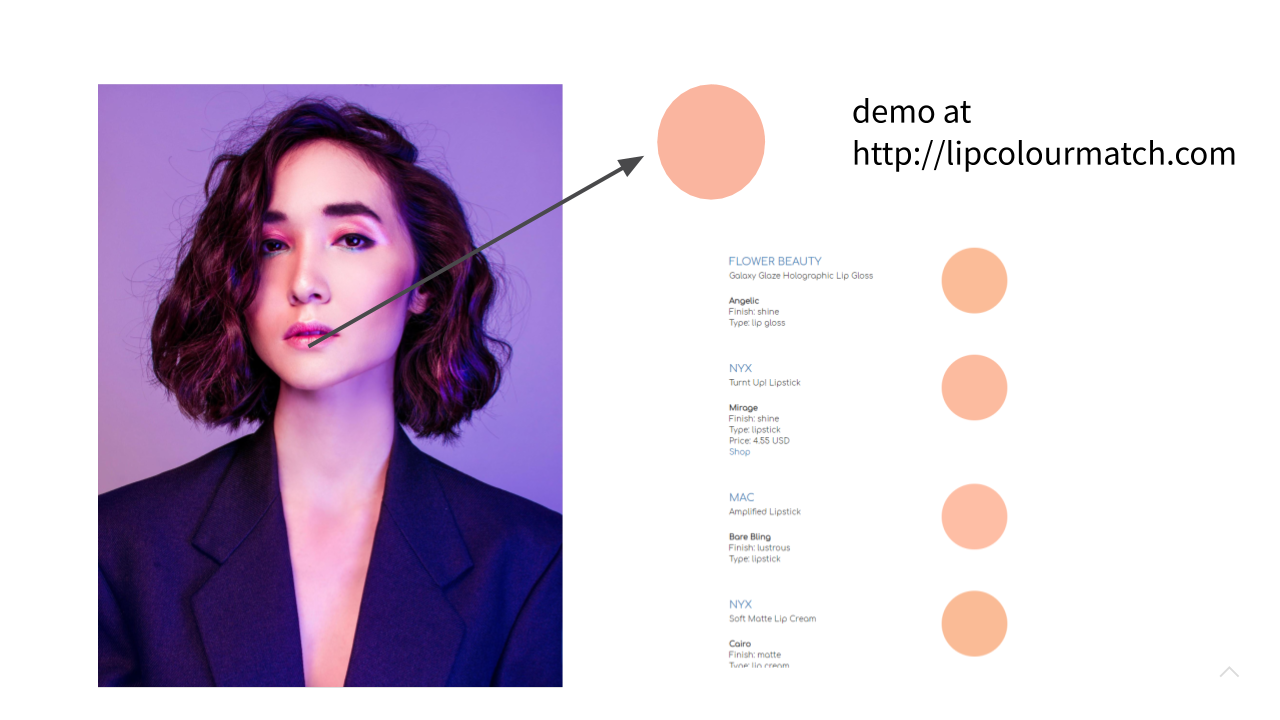
Instead, what we want is something closer to this. We pass in an image as the search query and the result is a list of lipcolour products that are potential colour matches.
Slide 12

There are very many parts that go into building a product that could be a lipcolour search engine. You have to think about the user interface. Since we’re not dealing with text searches, we have to think about the kinds of UI elements that could be intuitive to use for a user searching for colour. We have to think about the search workflow. The backend. Lots of things. However, in this talk, I’m simply going to focus on how to build the engine that powers the search engine and there are two components to this engine. First, you need a database of things to search for. For Google, this database consists of websites it has crawled and indexed. For us, this will be a database of lip products and the colours they consist of.
The second part of the engine that powers the lipcolour search is the similarity algorithm. This algorithm will determine which lip products in the database have a colour shade that is close enough to the original colour. And here is where we start running into challenges, because as it turns out determining programmatically which two colours are close enough to each other is not as straightforward as it seems to us.
Slide 13
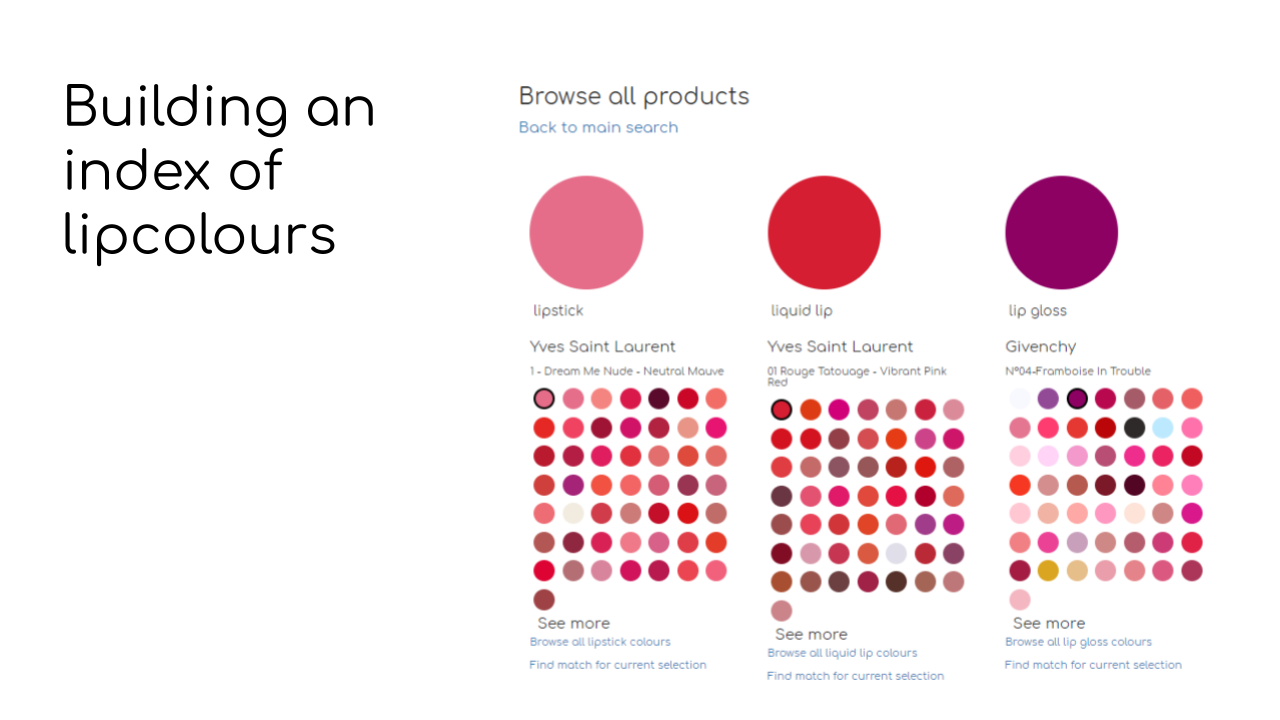
But first, let’s talk about the first part. How do we build a database of colours that we can use to search?
Slide 14
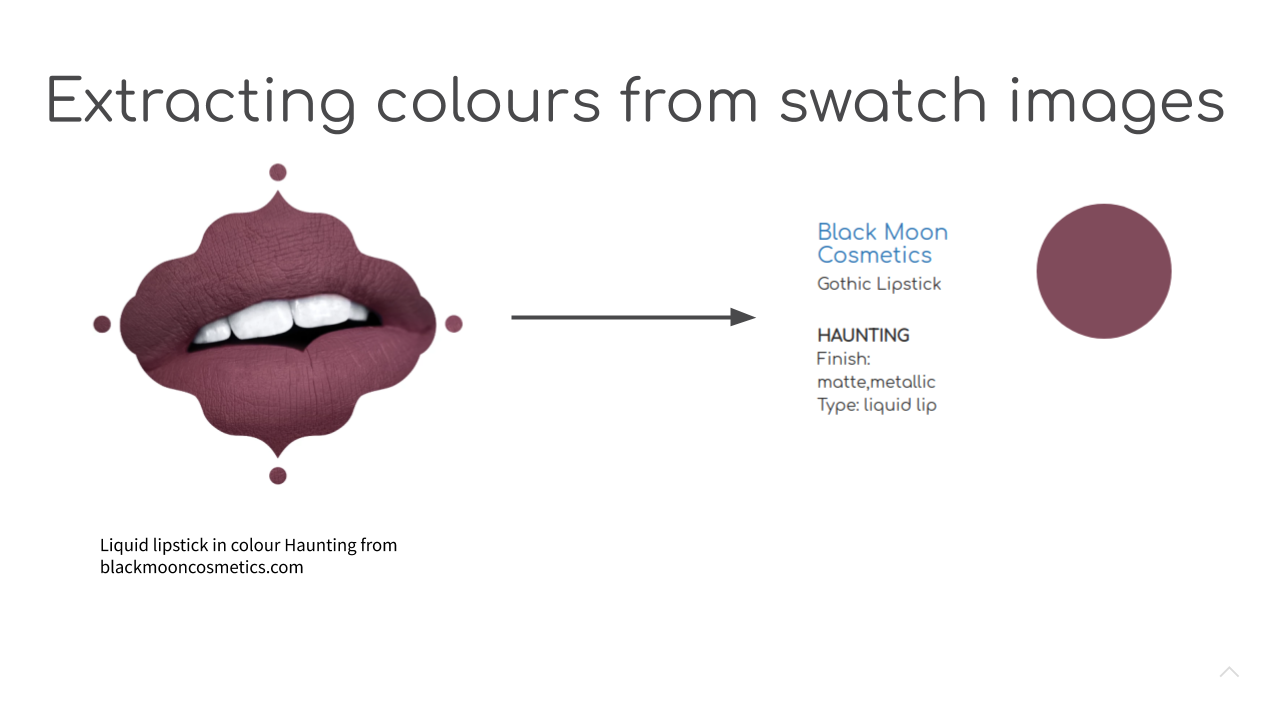
When brands release new lipcolour shades, they often update their websites with sample images of what the colour looks like either on the lips or on another part of the skin. We can take this image, extract the relevant area. What remains, then, is finding a representative colour that sums up all of these pixels. While this may seem like a trivial problem to the human eye (and brain), for a computer program this is more challenging …
Slide 15

because when a computer looks at an image of a lipcolour swatch, all it can see is a two dimensional array of RGB pixel values. Moreover, the colours present in this image are actually not homogenous.
Slide 16

If we plot all of the individual pixels present in this matrix that represents the image, we can see that there actually lots of different colours represented. Thus in order to get a colour that best summarizes this collection of pixels, we use something called a clustering algorithm. A good Python library that has implementations of many common clustering algorithms is scikit-learn.
Slide 17

The specific clustering algorithm used in this case is KMeans and what it does, is it groups the pixels in the image intro groups based on some similarity metric. In this case, the similarity metric is colour similarity. A pixel is assigned to a group based on how similar its colour is to the average colour of other pixels in the group. Once this grouping procedure is complete, we take the center (or the avg colour) of the group with the largest number of pixels. The KMeans algorithm requires one parameter and that is the number of groups you want the algorithm to find when arranging the pixels. Based on empirical observations, setting the number of groups (or number of clusters ) to four will give good results for most types of lipcolours. The only colours where this kind of procedure of summarizing a lipcolour with just one RGB value gets problematic are metallic lipcolour shades.
Slide 18

After you’ve repeated this clustering procedure for many, many lipcolours and stored the majority colours in each product into a database, you are ready to move into the next stage of building the engine that powers the search experience and that is, of course, the colour similarity algorithm.
Slide 19

As humans, we are generally quite good at answering questions like this. Our eyes and brains have built-in ways of recognising when one object is of a similar colour as another object, but for a computer this becomes more complicated. For most computer programs, a colour is just a list of three numbers, the amount of red, green and blue present in the image. So when presented with two such lists representing two different colours, a computer program has to find a way to calculate how close the two colours are.
Slide 20
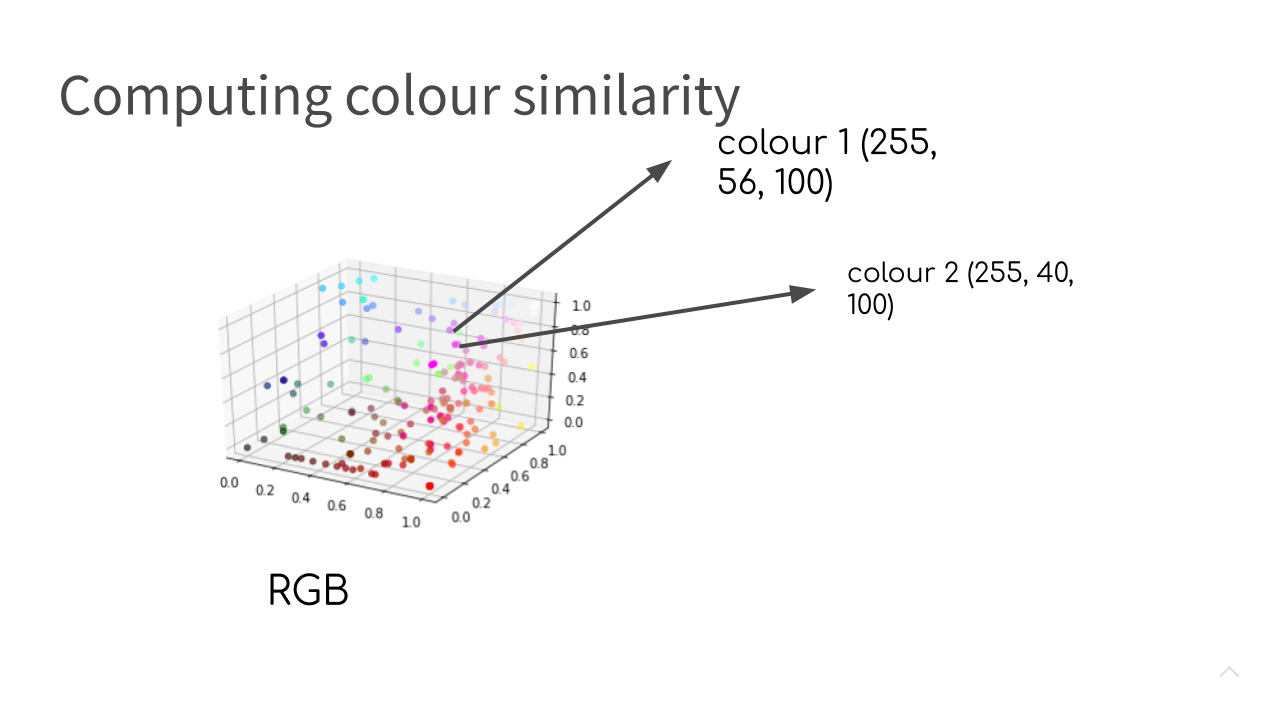
To make this problem a bit more concrete, let’s assume that these three measurements: the amount of red, green and blue that make up a given colour are analogous to height, width and depth of a cube. Then we can represent each lipcolour in our database as a point (or a vector) in this three dimensional cube (or RGB colour space, if we want to be more technical). Once we represent the problem like this, we might start to get some ideas of how to measure the similarity of the two colours.
As a very simple starting point, we might simply decide to compute the Euclidean distance between two colour vectors. If the distance is smaller than some constant X, we can conclude that the colours are similar enough to each other.
Slide 21
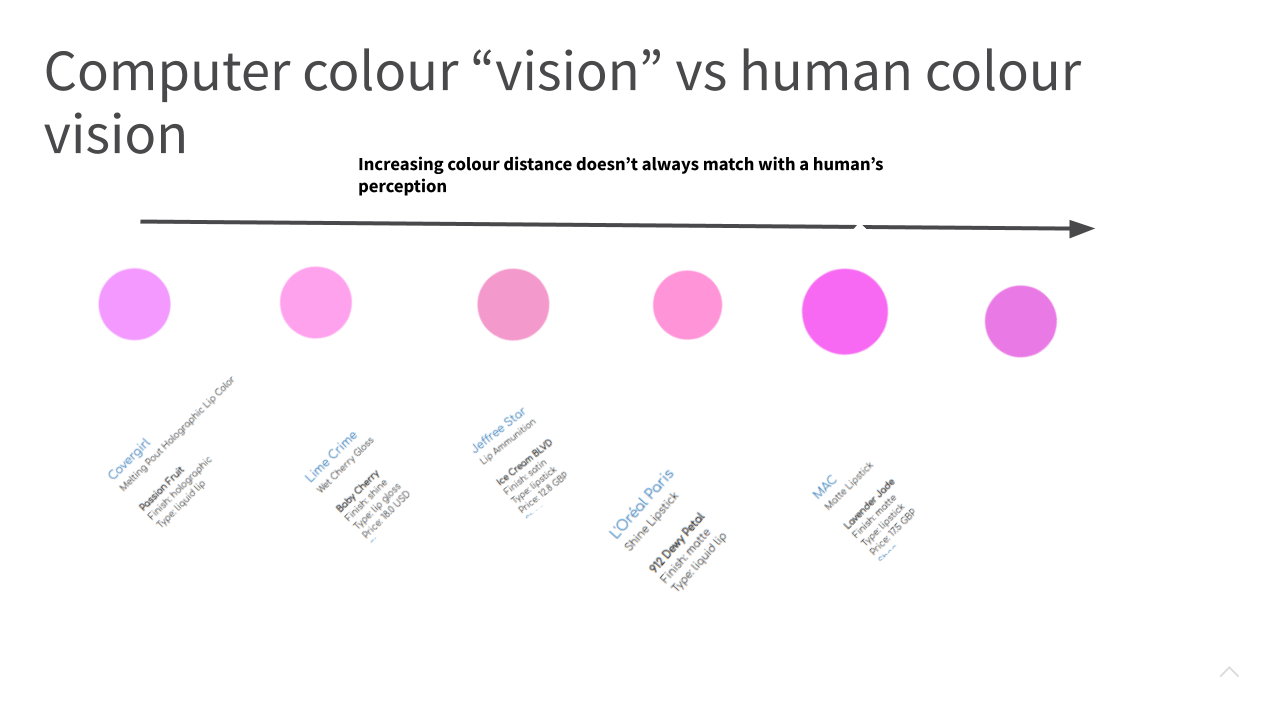
One big assumption that we made in the last slide was that colours that are close to each other in the RGB cube are also close to each other in the human visual system and this is not always the case. For example, using Euclidean distance in RGB space would lead us to rank the colours in the slide in order of increasing distance from left to right. And as you can see some colours that appear far apart in RGB space can, to a human, eye still appear very similar. So the way a computer vision algorithm sees things can be very different to the way a human eye sees colour. In fact, there may even be individual differences in how two people perceive colour similar. This is something to keep in mind when developing colour similarity measures.
Slide 22
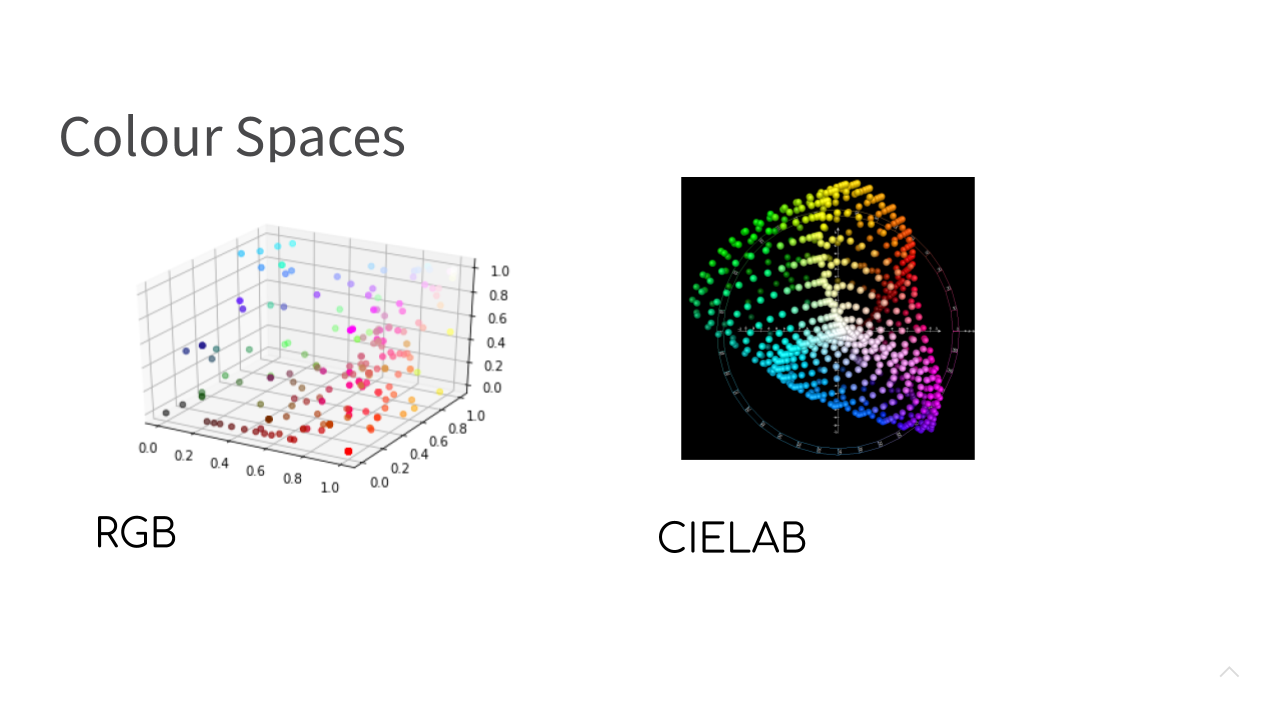
One way to work around this potential limitation is to use a colour space different to RGB. One suggested alternative that better captures the human visual system is a colour space known as CIELAB. There are Python implementations (such as scikit-image) available that will allow you to transform between a colour represented in RGB space and a colour represented in CIELAB space. During the early versions of developing the colour search engine, I experimented with search results using Euclidean distances in RGB space and Euclidean distances in CIELAB space, but found little differences in quality of results for most common lipstick colours.
Later on, I’ve noticed that the quality of results in RGB space, in particular, for lipsticks in pastel colours is quite poor, so I am definitely going to give another attempt at using CIELAB.
Slide 23

In addition to the problem of computer colour vision being quite different than human colour vision, what were some of the other challenges that came up?
Slide 24

Lipcolour products come in a variety of colours, but also in a variety of finishes: shine, matte, satin, pearl, velvet, sheer, cream and metallic. The final way a product looks on the lips can be strongly influenced by the finish. For example, a matte lipstick won’t reflect colour as much as a metallic or a pearl lipstick and so will likely have a more intense colour payoff. Same can be said for a cream lipstick and a matte lipstick. In the image on the slide, we have the same shade name in a matte liquid lip format and a cream/satin lipstick format (both of these images are of the colour Nahz Fur Atoo from the brand Kat Von D). As you can see, the shades appear slightly different.
Slide 25

Moreover, the skintone of the wearer can affect how the colour looks on the lips. The beauty industry has historically been largely geared towards people with lighter skins shades and this is often reflected in the shade ranges developed by brands and also in the available swatches. It should also be taken in account in a lipstick search engine, because users will be searching for colours that look a certain way on their lips, but may end up finding colours that will look different, because the search engine has been constructed using source data that was gathered from individuals with a different skin tone.
Slide 26
Thank you very much! If you want to know more, please follow the lipcolourmatch.com beauty blog or our Instagram page.